On the popularity of Unicode: percentages are not raw numbers
by Michael S. Kaplan, published on 2008/05/11 03:01 -04:00, original URI: http://blogs.msdn.com/b/michkap/archive/2008/05/11/8484991.aspx
There has been a lot of recent buzz based on the Moving to Unicode 5.1 post in the googleblog written by Mark Davis.
Enough that people keep sending me email asking if I had seen it, much of that traffic being there because I haven't blogged about it myself yet....
One of the most interesting points in the blog was about the Uptick in native Unicode webpages:
Just last December there was an interesting milestone on the web. For the first time, we found that Unicode was the most frequent encoding found on web pages, overtaking both ASCII and Western European encodings—and by coincidence, within 10 days of one another. What's more impressive than simply overtaking them is the speed with which this happened; take a look at the blue line in this graph.
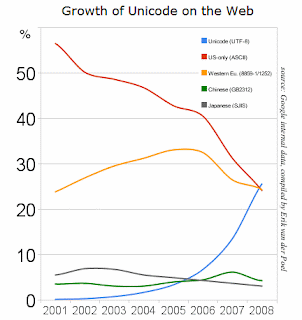
You can see a long-term decline in pages encoded in ASCII (unaccented letters A through Z). More recently, there's been a significant drop in the use of encodings covering only Western European letters (ASCII and a few accented letters like Ä, Ç, and Ø). We're seeing similar declines in other language-specific encodings. Unicode, on the other hand, is showing a sharp increase in usage.
This is based on our indexing of web pages, and thus may vary somewhat from what other search engines find. However, the trends are pretty clear, and the continued rise in use of Unicode makes it even easier to do the processing for the many languages that we cover.
The fact that we are really only looking at percentages here might make it easier for a company like Google to make resource allocation decisions based on web content encoding that they have to index.
But conclusions about growth (as the title of the art implies) might be a bit much, since there are other crucial factors here which Google has access to but is not provided in this quick example -- factors like
- the raw number of pages with each encoding, and
- the parts of the world where traffic is coming from, and
- the correlation (if any) between encoding and part of the world, and
- the type of web page (static HTML, blog, whatever), and
- other trends in the data that can be measured
would make it much easier to assess whether we are looking at an interesting phenomenon or an uptick in the number of web sites created by a particular tool used all over China or India, or an uptick in the number of blogs created in blogspot, or whatever.
I just don't want to draw conclusions of a multi-dimensional issue based on looking st just one dimension -- the encoding of pages (because while that is perfectly reasonable if one is looking what encodings to put resources in, it is not as interesting for making conclusions about the overall web -- since the reasons may have to do with entirely different issues).
This blog brought to you by ಝ (U+0c9d, aka KANNADA LETTER JHA)
# Jeroen Ruigrok van der Werven on 11 May 2008 6:49 AM:
So, can you get any similar data from the Live guys?
# Michael S. Kaplan on 11 May 2008 7:08 AM:
Possibly; I have not investigated yet.
The initial stage is just my "being critical of unscientific conclusions" behavior. :-)
# Matt Rhoten on 11 May 2008 1:06 PM:
It seems to be that a more interesting measure would be the international-ness of the content.
For example, a page encoded in UTF-8 whose content would fit in ISO-Latin-1 (or even ASCII) is only trivially a Unicode page. But if that page contained substantial amounts of content not encodable in ASCII, that's a little more interesting!
Lots of people working on currently English-only sites have designs on worldwide content down the road. These people are reflected in the chart, which seems to indicate that UTF-8 adoption is taking place at the expense of Western encodings (raw page counts would help clarify this). I applaud these people for getting the infrastructure in place to be truly worldwide.
# Michael S. Kaplan on 11 May 2008 1:55 PM:
Exactly -- there are so many interesting ways one could establish the ACTUAL patterns here, if only the real info were provided....
# John Cowan on 11 May 2008 2:54 PM:
My guess -- and that's all it is, a guess -- is that the encodings represent encodings-in-use rather than declared-encodings, such that something declared UTF-8 but only using the ASCII repertoire would be labeled ASCII on this chart.
Disclaimer: I work for Google, but not on search or i18n.
# int19h on 11 May 2008 3:02 PM:
This is not at all surprising, since most Web authoring tools these days usually default to UTF-8.
Please consider a
donation to keep this archive running, maintained and free of advertising.
Donate €20 or more to receive an offline copy of the whole archive including all images.
go to newer or older post, or back to index or month or day
